2015-08-03 from---https://www.landiannews.com/archives/18661.html GVLK密钥是专门用于KMS激活的密钥,如果想使用KMS激活,那么必须先将系统的KEY替换为对应版本的GVLK密钥。 KMS不仅可以激活Windows 8、Windows 8.1和Windows 7、Windows 10这类我们常用的系统,还可以激活各种版本的Windows Server系统。 以下是GVLK密钥版本对照表,可配合KMS服务器进行使用。 Windows 10 (注:由于Win Server 2016还未发布,所以这里暂时没有它的密钥) 操作系统 GVLK密钥 Windows 10 Professional W269N-WFGWX-YVC9B-4J6C9-T83GX Windows 10 Prof…
2011.09.01 from---http://luckerme.com/archives/588.html 相信大多数的天朝上网用户,使用网络的方式都是ADSL拨号上网,这样上网每次拨号获取的公网IP一般都是不同的。但是,如果你需要在动态公网IP下搭建一个可以随时随地访问的服务器(比如:建立WEB服务、FTP服务、Email服务、游戏服务器、视频服务、VPN、远程控制、网上电台、 数据动态传输等等 ),那么你就需要使用动态域名解析服务了。 动态域名解析服务 动态域名解析服务,简称DDNS(Dynamic Domain Name Server),是将用户的动态IP地址映射到一个固定的域名解析服务上,用户每次连接网络的时候,客户端程序就会通过信息传递把该主机的动态IP地址传送给位于服务商主机上的服务器程序,服务程序负责提供DNS服务并实现动…
2011 from---http://blog.sina.com.cn/s/blog_5ef3b2860100tiqk.html 有人说下载不了,我听了这个说法后第一时间是检查自己是不是真的错了,很遗憾,完全可以下载,这是2011年9月15日下载测试截图: http://www.oneleech.us/ 非常简单的做法:复制下载地址 > 再粘贴地址 > 再点击分析 > 再点下载就完了.其它没什么要说的了..... 以上为2011年9月15日早上测试修改文章内容! 以下为原文内容。 亲:很多网盘下载不了已成事实,多次发布下载方法都遭封杀。 这里共享6个网盘中转站,你肯定喜欢的。 网盘中转站的意思就是将那些所有的网盘资源,转存到这些中转站里,再去中转站下载,简单易用,下载快速无限制,还可以用迅雷哦....所有中转站…
Debian 全球镜像站 https://www.debian.org/mirror/list StableUpdates https://wiki.debian.org/StableUpdates StableProposedUpdates https://wiki.debian.org/StableProposedUpdates SourcesList https://wiki.debian.org/SourcesList Debian 8 -- Errata https://www.debian.org/releases/jessie/errata NvidiaGraphicsDrivers https://wiki.debian.org/NvidiaGraphicsDrivers CreatePackageFromPPA https…
下一主题 谈谈主从分布式爬虫与对等分布式爬虫的优劣
动态网页数据抓取踩坑分享
Python书籍推荐
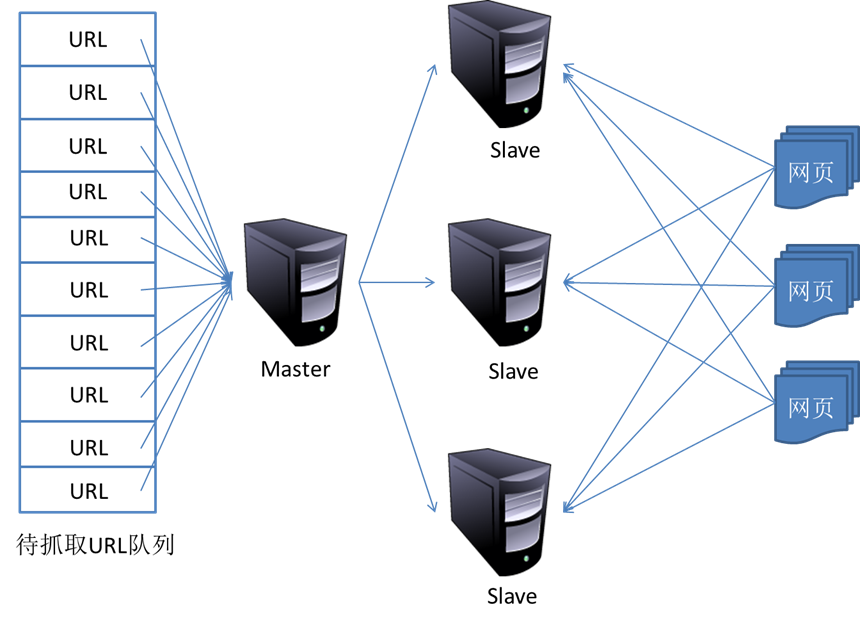
2015-8-2 18:50 from---http://www.dataguru.cn/thread-529666-1-1.html 主从式(Master-Slave) 对于主从式而言,有一台专门的Master服务器来维护待抓取URL队列,它负责每次将 URL分发到不同的Slave服务器,而Slave服务器则负责实际的网页下载工作。Master服务器除了维护待抓取URL队列以及分发URL之外,还要负责调解各个Slave服务器的负载情况。以免某些Slave服务器过于清闲或者劳累。这种模式下,Master往往容易成为系统瓶颈。 对等式(Peer to Peer) 在这种模式下,所有的抓取服务器在分工上没有不同。每一台抓取服务器都可以从待抓取在URL队列中获取URL,然后对该URL的主域名的hash值H,然后计算H mod m(其中m是服务器的…
Sep 13, 2016 from---https://xuanwo.org/2016/09/13/dynamic-page-data-spider/ 之前做了一些数据抓取的工作,期间也踩了一些坑,所以有了这篇文章。 动态网页数据源获取 需要抓取的页面是使用React JavaScript 框架开发的,所有的页面都是客户端渲染而成,这也就导致我只能看到一个个的 data-id ,没有办法直接获取数据。这就涉及到一个我之前没有接触过的领域——动态网页爬虫。 一番 Google 之后,我了解到动态网页爬虫大致上可以通过以下两种方法实现: 分析网页代码结构和请求,找到数据源的请求链接 调用Webkit渲染之后再进行抓取 第二种方法相当于在命令行中跑一个浏览器,一个页面一个页面的打开,效率可想而知。再加上待抓取页面的 DOM 结构本来就比较复杂,没…
2016 from---https://zhuanlan.zhihu.com/p/22198827 1 年前 从2011年5月买了第一本《Python学习手册(第四版)》开始,我阅读过大量和Python有关的纸质书和开源图书。为什么要买书来看?我认为不外乎两个原因:有趣和能学到东西。技术书肯定不会太有趣,那么最重要的就是能学到东西。市面上Python相关的书相当多,但是有些内容陈旧或者不符合国情,经常能看到并非开发第一线的人写或者翻译的书,这些书显然价值就要低一些;其次是同质化和向入门级别靠拢,市面上关于Python入门或者教授语法知识的书不少,而再深入一点的就很匮乏了。还有一点,现在为了提高书的销量,书名都起的非常有破坏力,很吸引眼球,可是内容完全不够书名的档次。不知道一些回答推荐书籍问题的人是怎么想的,反正话说起来很廉价,又不用负责。但…